조인(join)
두 릴레이션간 관련된 투플들을 결합하여 하나의 투플로 만드는 연결방법으로써, 두 개 이상의 릴레이션을 갖는 관계 데이터 베이스에 대해서 릴레이션들 간의 관계를 처리할 수 있게 한다.
=> 여러래의 테이블에 저장된 데이터를 한번에 조회할 수 있다.
일반적인 조인과정
학생의 학과 이름을 알고 싶을 경우
학과
학과 번호 |
학과 이름 |
학과 설명 |
학과 전화번호 |
01 |
컴퓨터공학과 |
컴돌이 육성과 |
010-1234-5678 |
02 |
경영학과 |
문과면 당연히 경영이지 |
010-1235-5678 |
03 |
통계학과 |
계산기 마스터 |
010-1236-5678 |
학생
학생 고유 번호 |
학생 이름 |
학생 학년 |
학과 번호 |
001 |
홍길동 |
2 |
01 |
002 |
이춘향 |
1 |
02 |
이렇게 학과 번호가 같은 것을 찾아서 조인과정을 거칩니다.
쿼리로 짠다면 아래와 같습니다.
Select * from 학과, 학생
Where 학과.학과번호 = 학생.학과번호
이와 같은 조인을 할 때 사용되는 연산방법들이 4가지 있습니다.
1. 중첩 반복조인 (Nested Loop join)
2. 색인된 중첩 반복 조인. 단일 반복조인(single loop join)
3. 정렬 합병 조인 (Sort Merge join)
4. 해시 조인(Hash join)
1. 중첩 반복조인(Nested Loop join)
: 2개 이상의 테이블에서 하나의 집합을 기준으로 순차적으로 상대방 Row를 결합하여 원하는 결과를 추출한다.
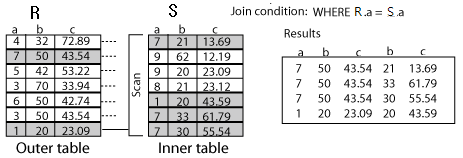
즉 Outer table의 기준으로 Inner 테이블의 조건에 만족하는 데이터를 추출한다.
특징
1. 주로 좁은 범위에 유리
2. 순차적으로 처리하며, Random Access 위주
3. 후행(Driven) 테이블에는 조인을 위한 인덱스가 생성되어 있어야 한다.
4. 실행속도= 선행 테이블 사이즈 * 후행 테이블 접근 횟수
주의사항
1. 데이터를 랜덤으로 액세스하기 때문에 결과 집합이 많으면 수행속도가 저하됨
2. 선행(Driveing) 테이블의 크기가 작거나, Where절 조건을 통해 결과 집합을 제한할 수 있어야 한다.
3. 조인 연결고리 인덱스가 없거나, 조인 집합을 구성하는 검색 조건이 조인 범위를 줄여주지 못할 경우 비효율적이다.
2. 정렬 합병 조인(Sort Merge Join)
: R과 S의 레코드들이 각각 조인 애트리뷰트 A,B값에 따라 물리적으로 정렬되어 있는 경우, 두 파일을 모두를 조인 애트리 뷰트의 순서에 따라 동시에 스캔하면서 A, B 값이 동일한 레코드를 검색한다.
정렬되어 있지 않은 경우는 우선 외부 정렬을 사용하여 정렬 후 조인
조인의 대상 범위가 넓을 때 발생하는 랜덤 액세스를 줄이기 위한 경우나 연결고리에 마땅한 인덱스가 존재하지 않을 때 해결하기 위한 대안
Sort Merge Join 특징
1. 연결을 위해 랜덤 액세스를 하지 않고 스캔을 하면서 이를 수행
2. 정렬을 위한 영역에 따라 효율에 큰 차이가 남
3. 조인 연결고리의 비교 연산자가 범위 연산인 경우 Nested Loop 조인보다 유리
Sort Merge Join 주의 사항
1. 두 결과집합의 크기가 차이가 많이 나는 경우에 비효율적
2. Sorting 메모리에 위치하는 대상은 join key 뿐만 아니라 Select list도 포함되므로 필요한 select 항목 제거
3. 해시 조인(Hash join)
- 해싱 함수(Hashing Function) 기법을 활용하여 조인을 수행하는 방식으로 해싱 함수는 직접적인 연결을 담당하는 것이 아니라 연결될 대상을 특정 지역에 모두는 역할만 담당함
- R의 애트리뷰트 A와 S의 애트리뷰트 B를 해시 키로 하고 동일한 해시 함수를 사용하여 해시
- 1단계(분할 ,partitioning phase) : 더 적은 수의 레코드를 가진 화일(R)의 레코드들을 해시 파일 버켓들로 해시
- 2단계(조사 ,probing Phase) : 다른 파일(S)의 각 레코드를 해시하여 R에서 동일한 해시 주소를 갖는 버켓 내의 레코드들이 실제로 조인 조건을 만족하면 두 레코드를 결합
Hash join의 특징
1. Nested Loop 조인과 Sort Merge 조인의 문제점을 해결
2. 대용량 처리의 선결조건인 랜덤 액세스와 정렬에 대한 부담을 해결할 수 있는 대안으로 등장
3. Hash 조인만을 이용하는 것 보다 parallel processing을 이용한 hash조인은 대용량 데이터를 처리하기 위한 최적의 솔루션 제공
4. 2개의 조인 테이블 중 small rowset을 가지고 hash_area_size에 지정된 메모리 내에서 hash table 생성
5. Hash bucket이 조인집합에 구성되어 Hash 함수 결과를 저장하여야 하는데, 이러한 처리에 많은 메모리와 CPU자원이 소모됨
6. CBO(Cost Based Optimizer) 모드에서 옵티마이저가 판단가능하며, 테이블의 통계정보가 있어야 함
7. Hash table 생성 후 Nested Loop처럼 순차적인 처리 형태로 수행함
Hash Join사용시 주의사항
1. 대용량 데이터 처리에서는 상당히 큰 hash area를 필요로 함으로, 메모리의 지나친 사용으로 오버헤드 발생 가능성
2. 연결조건 연산자가 ‘=’인 동치조인인 경우에만 가능
Hash join
1) 수행 순서
- 두 테이블을 스캔하여 사이즈가 작은 테이블을 선행 테이블로 결정
- 선행 테이블을 이용하여 해쉬 테이블을 구성한다(Build Input)
- 후행 테이블은 해쉬 값을 이용하여 선행 테이블과 조인한다(Prove Input)
2) Build Input 크기
- Hash Area 만으로 Hash Table 생성이 불충분하다면 Hash Table Overflow가 발생
- 내Hash Area 사이즈를 증가 필요함
3) 이용
- 대용량 데이터 엑세스, 배치처리, 전체 테이블을 조인할 때 유리하다
- 양쪽 테이블의 조건으로 각각 범위를 줄일 수 있을 때 유리하다
- 병행 처리로 수행속도 향상이 가능하다
- Hash Are
a 사이즈 조정으로 수행속도 향상이 가능하다
조인의 비교
|
Nested Loop join |
Hash join |
대용량의 범위 |
인덱스를 랜덤 액세스에 걸리는 부하가 가장 큰 문제점으로, 최악의 경우 하나의 Row를 액세스하기 위해 Block단위로 하나하나 액세스를 해야한다. |
적은 집합에 대하여 먼저 해시 값에 따른 Hash Bucket정보를 구성한 후 큰 집합을 읽어 해시 함수를 적용하여 Hash Bucket에 담기 전에 먼저 호가인해 볼 수 있기 때문에 해시 조인이 효율적인 수행이 가능
|
대량의 자료 |
다량의 랜덤 액세스 수행으로 인해 수행 속도 저하 |
대용량 처리의 선결 조건인 '랜덤액세스'와 '정렬' 에 대한 개선과 H/W 성능 개선을 통해 각 조인 집합을 한번 스캔하여 처리하기 때문에 디시크 액세스 면에서 훨씬 효율적 |
출처
http://www.jidum.com/jidums/view.do?jidumId=167
'프로그래밍 > Database' 카테고리의 다른 글
| (데이터베이스) DBS의 이해 (0) | 2018.12.02 |
|---|---|
| (데이터베이스) DBMS 정의 및 개요 (0) | 2018.12.02 |
| [Mysql Workbench] Update,Delete 쿼리 실행 시 오류 (0) | 2018.11.21 |
| [데이터베이스] Grant와 Revoke(사용자에게 권한부여) (0) | 2018.11.21 |
| [MySQL] UTF8 한글깨짐 오류 해결법 (0) | 2018.11.21 |


